A few years ago, “shadow IT” meant somebody in marketing buying a SaaS tool without telling procurement. Now it means somebody in marketing deploying software.
That is the real story behind this WIRED investigation into thousands of exposed vibe-coded applications built using tools like Lovable, Replit, Base44 and Netlify.
Most people reading the article will focus on the obvious headline: insecure AI-generated applications exposing customer data, hospital records, internal documents and company systems publicly on the internet.
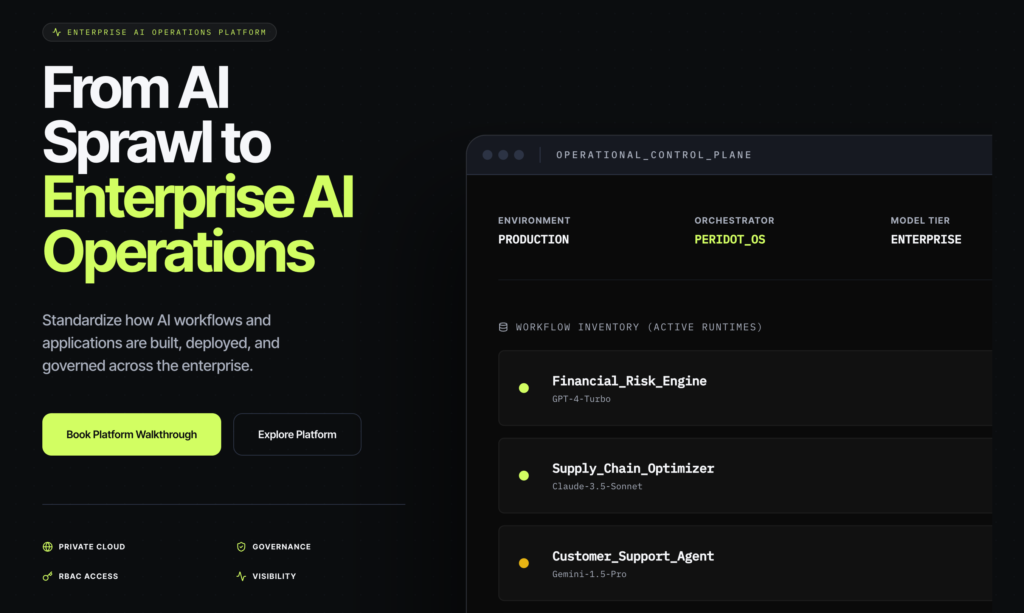
But I think the more important observation is hidden underneath it. For the first time in enterprise history, the people capable of deploying production software are no longer just engineers. That changes the entire security model of the enterprise.
For twenty years, companies accidentally relied on engineering scarcity as a governance mechanism. Software creation was slow because software creation required specialists. You needed developers, infrastructure teams, deployment pipelines, QA, security reviews, staging environments, procurement approvals and architecture discussions. Everybody hated that process because it slowed things down. But the slowness itself acted as protection.
Now a recruiter can build an AI candidate screening tool in 30 minutes. A RevOps person can build a lead routing system over the weekend. A marketer can create an internal chatbot connected to CRM data before lunch. A founder can connect Google Drive, Slack, HubSpot and OpenAI together into a live workflow without ever speaking to engineering.
The article captures something most people still do not fully appreciate: these tools are no longer helping people prototype. They are helping people deploy. That is a massive difference.
The dangerous part is not merely that the code may contain vulnerabilities. Traditional software has always had vulnerabilities. The dangerous part is that the people deploying these systems often do not even think of themselves as deploying software infrastructure. They think they are “making a tool.” That mental framing matters because it bypasses all the caution organizations historically built around production systems.
A non-technical employee does not naturally think about RBAC models, authentication boundaries, exposed APIs, secret management, audit logging, public routing, prompt injection, external access controls or tenant isolation. And AI coding systems do not inherently force those conversations either because their core value proposition is speed, not governance.
That is why the comparison in the article to Amazon S3 bucket leaks is so important. The S3 era taught the industry that if infrastructure becomes dramatically easier to create than to secure, then misconfiguration stops being an edge case and becomes systemic. Companies like Verizon, Accenture and WWE accidentally exposed sensitive data not because they lacked security teams, but because cloud infrastructure creation became democratized faster than security understanding spread through organizations.
Vibe coding is now doing the same thing to software itself.
Except this wave is potentially much larger because applications are not passive storage systems. Applications have permissions, workflows, integrations and actions. They connect to customer systems. They automate decisions. They trigger communications. They access internal context. They become operational infrastructure extremely quickly.
And enterprises are nowhere near ready for the scale of this shift.
Most CIOs still think “Shadow AI” means employees pasting confidential documents into ChatGPT. That framing already feels outdated. What is actually emerging is operational AI sprawl: thousands of small AI-powered internal applications appearing across organizations outside traditional development processes.
The important detail in the WIRED piece is not just that thousands of exposed applications were found. It is how easy they were to discover. Researchers simply searched public domains associated with these platforms and found production systems sitting openly on the internet. That suggests the problem is not isolated incompetence. It suggests the default organizational behavior around AI-generated software is currently immature.
And honestly, this makes sense. We are still culturally treating vibe coding as experimentation. But businesses are already treating it as infrastructure. That mismatch is dangerous. The irony is that the AI industry spent two years debating whether models would replace software engineers, while the more immediate reality is that AI dramatically expanded the number of people capable of creating software without understanding software operations.
That may ultimately become the bigger enterprise disruption.
Because once software creation escapes engineering departments, the old governance models stop working. Security teams cannot review every application manually if software generation becomes ambient inside organizations. The old workflow of ticket → backlog → sprint → deployment review breaks when software can appear instantly from a prompt.
Which means the next major enterprise category may not be “AI coding.” It may be enterprise AI governance infrastructure. Not tools that merely help people generate apps, but systems that answer questions enterprises suddenly care deeply about:
Who created this application?
What data sources is it connected to?
Which models are being used?
Where is the data flowing?
Is the app externally exposed?
Can we audit activity?
Can we centrally revoke access?
Can we prevent sensitive data leakage?
Can we force deployment inside enterprise infrastructure instead of public hosting?
Those questions barely mattered in consumer vibe coding.
They become existential in enterprise environments.
And that is why this article matters much more than “AI-generated apps may expose data.”
The deeper story is that AI quietly transformed software deployment from a specialized organizational function into a general employee capability.
Most companies have not fully processed the consequences of that yet.